微信公众号

手机端

搜索




VR陀螺编译/Frida.WS
Facebook Reality Labs研发团队发表了一项关于超现实虚拟形象方法的详细研究论文,扩展了公司之前名为“编解码器化身”的工作项目。

.Facebook Reality Labs创建了一个系统,从简洁硬件中能够以目前最高的逼真度实时制作出动画版的虚拟化身。头显内只有三个标准摄像头,定位用户的眼睛和嘴巴,系统能够更准确地辨别出个体复杂的面部表情中的细微差别。
这项研究的重点不仅仅是如何将摄像机固定在头显上,还包括如何利用图片还原用户虚拟形象的深层技术。
系统方案主要依赖于机器学习和计算机视觉。“我们的系统是实时运行的,它可以识别各种各样的表情,包括鼓脸颊、张大嘴咬人、动舌头,以及还原皱纹这样的细节,在之前,这些细节很难精确地动画化,”一位作者说。
实验小组还发表了他们的完整研究论文,深入论述了系统背后的方法论和数学。这项名为《通过多视图图像翻译的VR面部动画》(VR Facial Animation via Multiview Image Translation)的研究成果发表在《ACM图形学报》(ACM Transactions on Graphics)上,这家杂志自诩为“图形领域最重要的同行评审期刊”。

1.带有9个摄像头的训练头显。
2.带有三个摄像头的追踪头显;红色圈起的摄像头可以与训练头显共享。
图片来源: Facebook Reality Labs
这篇论文解释了项目为何要创建两个独立的实验耳机,一个“训练”耳机和一个“追踪”耳机。
这款训练耳机体积较大,装有9个摄像头,可以收集用户面部和眼睛的更宽范围的视图。这样做可以简化输入图像和先前捕获的用户数据扫描之间的对应过程(分析输入图像与输出化身之间的对应部分)。论文称,这一过程可以“通过带有自查功能的多视图图像翻译系统自动匹配,不需要人工注释或域间逐个对应”。
一旦对应完成,就可以使用更紧凑的“追踪”头显。“追踪”头显的三部相机恰好对应着“训练”头显九部相机中的三部;根据“训练”头显收集的数据,这三部相机的视角可以得到更好的理解运用,也就是说,输入图像能够准确地驱动动画化身。
论文着重研究了系统的精准度。以前的输出方式一到关键区域,用户实际面部表情的准确性就会下降,尤其是极端表情,以及眼部动作和嘴部运动的关系。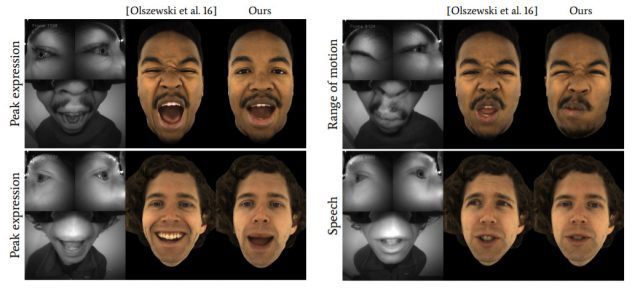
与之前相比,新系统的精准度明显提升:对于脸基本被头显遮住的用户来说,近距离的镜头可以用来准确地重建面部。
尽管功能进步明显,但现有方法仍然不容易被主流人群接受。因为前期要对用户进行详细的初步扫描,以及使用专业的“训练”头显,这就需要“扫描中心”这类的机构,用户可以去那里扫描和练习使用虚拟化身效果(同时也会获得一个定制的HRTF)。可是在虚拟现实成为社会交流方式的重要组成部分之前,我们不太可能建立这样的中心机构。然而,先进的传感技术和不断改进的自动通信建设或许可以让我们在家中完成这一步骤。
原文链接:https://www.roadtovr.com/facebook-expands-on-hyper-realistic-virtual-avatar-research/
投稿/爆料:tougao@youxituoluo.com
稿件/商务合作: 林南(微信 19250561593) 六六(微信 13138755620)
加入行业交流群:林南(微信 19250561593)

元宇宙数字产业服务平台
下载「陀螺科技」APP,获取前沿深度元宇宙讯息
































